

“VisualCortex” is the application responsible for the visual capabilities of Human-like AI platform “LUDENS”. Spatial information is mapped out like human vision to include movement, posture, facial expression, gaze, line of sight, and more. These characteristics are analyzed in real-time from the aggregated area.
Top Ranked in Major Competitions Worldwide
The visually specialized AI technology behind VisualCortex has achieved various results around the world.


Functions
- Detects and identifies human information on images in detail
- Lightweight, stand-alone AI for fast recognition speed and high security
- Runs on an inexpensive system (Jetson Nano™ + off-the-shelf camera)
Person Detection

Detects people and their locations in the image
Person Tracking

Track the same person across multiple frames and multiple people
Face Detection

Detects the face and position of a person in an image
Attention Detection

Detects a person's gaze and recognizes whether the person is gazing or not
Emotion Prediction

Estimates emotions from detected human facial expressions
Mask Detection

Detects whether or not someone has a mask on
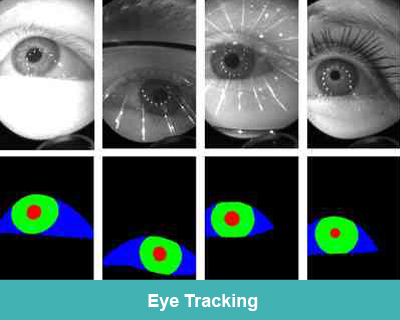
Gaze Estimation

Detects the direction of a person's gaze
How to use
A stand-alone, simple, inexpensive system that emphasizes speed and can be up and running immediately.

Recommending the Jetson Nano™
We recommend using the Jetson Nano™ module, a system-on-module that enables the development of small, low-cost, low-power AI devices. VisualCortex is designed for AI implementation in a variety of industries from smart cities to robotics. Reference: Jetson Nano™ official website

Commercially Available Cameras
VisualCortex is designed to work with common webcams available on the market. There is no need to purchase a special, dedicated camera.

JSON
Recognition results can be obtained in JSON (JavaScript Object Notation). It is a lightweight text-based data exchange format that can be used to link data to various external systems. It is also used in "LUDENS," a Human-like AI developed by Cougar. JSON Official Website
Functional Details
Person Detection
Detects people and their positions in an image
| Output | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Recognition probability | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Position | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Person Track
Detects and tracks the same person in the video
| Output | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Person ID | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Face Detection
Detects the face and position of a person in an image
| Output | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Recognition probability | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Position | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Attention Detection
Detects a person's line of sight and recognizes whether the person is gazing at it or not
| Output | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Attention flag (0 or 1) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Emotion Prediction
Estimates and predicts emotions based on detected human facial expressions.
| Output | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Recognition probability | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Emotion type |
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Mask Detection
Detects whether a mask is worn.
| Output | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Recognition probability | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Position | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

Contact Us


© Couger.co.jp. All rights reserved.